Abusing Google Safebrowse for phished credentials URLs
May 12, 2019When Google Safebrowse scans your site
I recently submitted a non existent page to Google Safebrowsing, using this link. The first result was largley as expected - a hit from a Google IP address scanning that page.
x.x.x.x - - [23/Apr/2019:08:11:30 +1000] "GET /iojoijiuoj HTTP/1.1" 404 7818 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36"What followed right after however was quite interesting, a large series of requests for interesting looking filenames on the same host. Some relevant snippets of the web server log can be seen below.
x.x.x.x - - [23/Apr/2019:08:13:38 +1000] "GET /dropbox.zip HTTP/1.0" 404 7818 "-" "python-requests/2.18.4"
x.x.x.x - - [23/Apr/2019:08:13:38 +1000] "GET /newphase.zip HTTP/1.0" 404 7818 "-" "python-requests/2.18.4"
x.x.x.x - - [23/Apr/2019:08:13:39 +1000] "GET /Doc.zip HTTP/1.0" 404 7818 "-" "python-requests/2.18.4"
x.x.x.x - - [23/Apr/2019:08:13:40 +1000] "GET /wp-content.zip HTTP/1.0" 404 7818 "-" "python-requests/2.18.4"
x.x.x.x - - [23/Apr/2019:08:13:40 +1000] "GET /auth.zip HTTP/1.0" 404 7818 "-" "python-requests/2.18.4"
x.x.x.x - - [23/Apr/2019:08:13:41 +1000] "GET /Pdf.zip HTTP/1.0" 404 7818 "-" "python-requests/2.18.4"
x.x.x.x - - [23/Apr/2019:08:13:42 +1000] "GET /secure-dropbox.zip HTTP/1.0" 404 7818 "-" "python-requests/2.18.4"
x.x.x.x - - [23/Apr/2019:08:13:42 +1000] "GET /dropbox2016.zip HTTP/1.0" 404 7818 "-" "python-requests/2.18.4"
x.x.x.x - - [23/Apr/2019:08:13:43 +1000] "GET /yahoo%202.txt HTTP/1.0" 404 7818 "-" "python-requests/2.18.4"
x.x.x.x - - [23/Apr/2019:08:13:44 +1000] "GET /adobe.zip HTTP/1.0" 404 7818 "-" "python-requests/2.18.4"
x.x.x.x - - [23/Apr/2019:08:13:45 +1000] "GET /mn.zip HTTP/1.0" 404 7818 "-" "python-requests/2.18.4"
x.x.x.x - - [23/Apr/2019:08:13:45 +1000] "GET /Dropbox.zip HTTP/1.0" 404 7818 "-" "python-requests/2.18.4"
x.x.x.x - - [23/Apr/2019:08:13:46 +1000] "GET /x.txt HTTP/1.0" 404 7818 "-" "python-requests/2.18.4"
x.x.x.x - - [23/Apr/2019:08:13:47 +1000] "GET /dhl.zip HTTP/1.0" 404 7818 "-" "python-requests/2.18.4"
x.x.x.x - - [23/Apr/2019:08:13:47 +1000] "GET /accepted_visitors.txt HTTP/1.0" 404 7818 "-" "python-requests/2.18.4"A early hypothesis here is that this a list of files Google found associated with known phishing kits.
Recreating this script
I’ve written a Ruby script which you can find here, which replicates this scan. With a bit of regex against my own log file, we can generate a list of just over 200 URLs that may be interesting to us.
You can find it here: https://gist.github.com/technion/cf433786d770e4a270e40f725f0e00e5
A good target
Anyone with access to a spam quarantine should have thousands of phishing URLs at the ready, and in most cases they are unreported. A good example was found in a URL involving the extremely heavily abused 000webhostapp.com domain. Although they were responsive to my reports and pulled the site down in literally minutes, I censored this full domain as I couldn’t guarantee the file involved wasn’t found in a search cache somewhere.
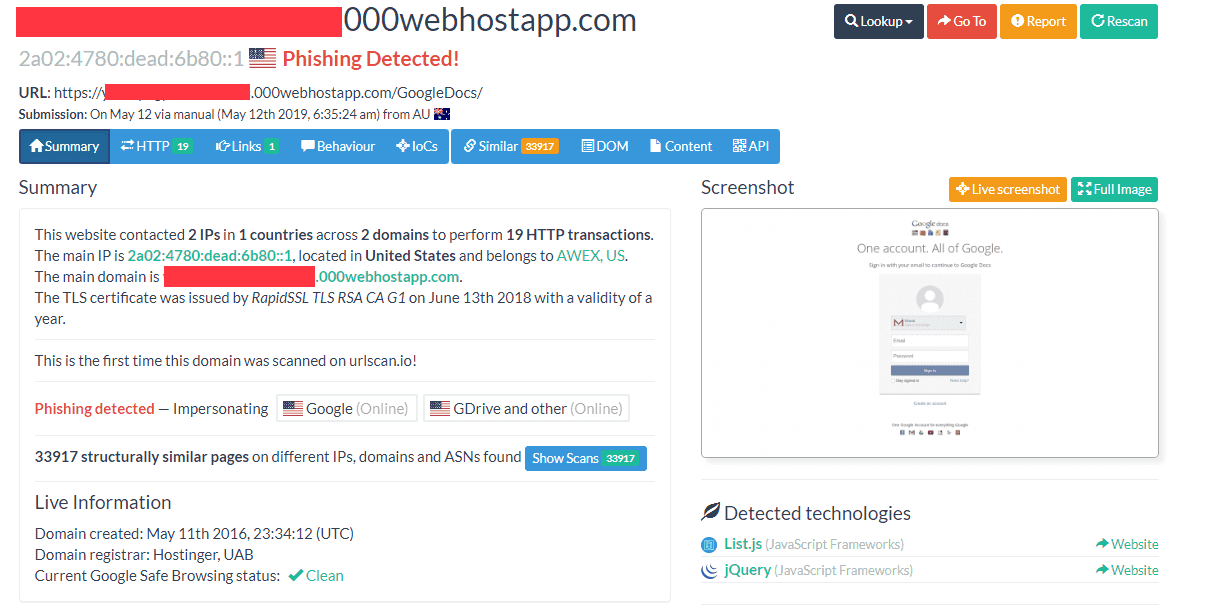
This is what it urlscan.io shows us about the site. Yep, that sure looks like phishing. And clearly brand new, and it’s “clean” here and according to virustotal. Let’s run our script against the domain:
$ ./phishget.rb https://xxx.000webhostapp.com/GoogleDocs
Interesting URL found: /melog-india.txt
Successfully scanned 217 URLsPhishing kits - and answers
The majority of the “interesting” URLs scanned, based on filenames at least, appear to be the zip files common phishing kits are distributed in. However, more interesting to us is the list of filenames that common phishing kits apparently store captured passwords in. Whilst the attacker themselves told us they had a phishing site, it’s this scan that helped us see that melog-india.txt is apparently a known place to dump credentials. Because it turns out that yes,
$ curl https://xxxx.000webhostapp.com/GoogleDocs/melog-india.txtDumps a big list of username/passwords to my screen.